Thomas Swearingen
Auto-Tuned Models (ATM)
A multi-user, multi-data model exploration system
Collaborators: Bennett Cyphers, Alfredo Cuesta-Infante, Will Drevo, Arun Ross, Kalyan Veeramachaneni
Project Description
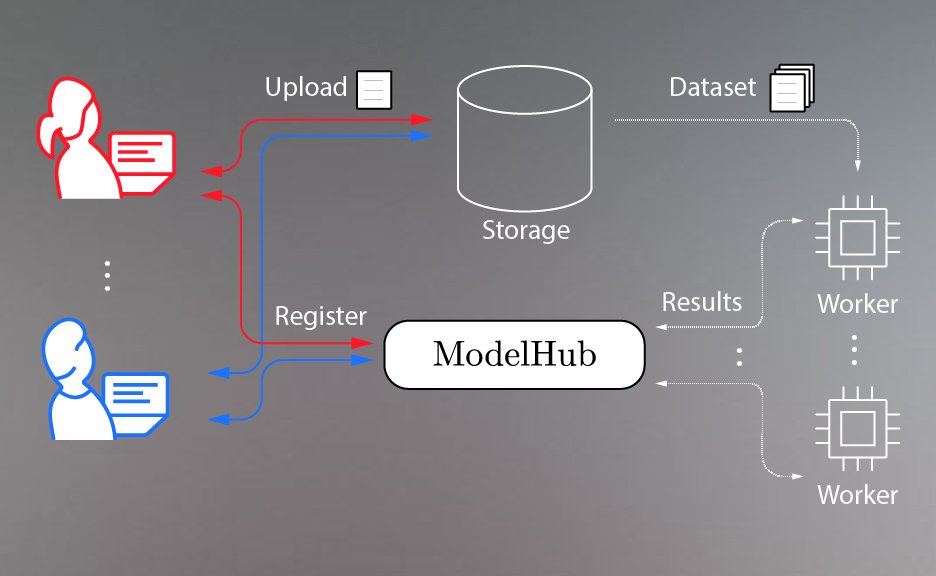
More Info
Additional information about this project may be found at the DAI project page for ATM.